In this example, we will create a Kafka Connect cluster, and a few connectors that consumes particular twitter topics and writes them to an elasticsearch index to be searched easily.
We are not going to deal with any custom resources of Strimzi.
Instead we will use traditional .property files that are used for Kafka Connect instances and connectors, with the help of Strimzi Kafka CLI.
- A Kubernetes/OpenShift cluster that has Strimzi Kafka Operator installed.
- A namespace called
kafka and a Kafka cluster called my-cluster
- An elasticsearch instance up and running in the same namespace.
(You can use the
elasticsearch.yaml file in the repository if you have the ElasticSearch Operator running.)
- A public image registry that has a repository called
demo-connect-cluster.
- Most importantly, a
Twitter Developer Account that enables you to use Twitter API for development purposes.
In this example we are going to use it with one of our Kafka Connect connectors.
-
This part of the repository.
Clone this repository to be able to use the scripts provided for this example.
As a recommendation create the namespace first:
$ kubectl create namespace kafka
Or you can use the new-project command if you are using OpenShift.
Then install the Strimzi Operator if its not installed.
You can use Strimzi CLI for this:
$ kfk operator --install -n kafka
Clone the repo if you haven't done before and cd into the example's directory.
$ git clone https://github.com/systemcraftsman/strimzi-kafka-cli.git
$ cd strimzi-kafka-cli/examples/5_connect
Create Kafka and Elasticsearch cluster by running the setup_example.sh script in the example's directory:
$ chmod +x ./scripts/setup_example.sh
$ ./scripts/setup_example.sh
This will create a Kafka cluster with 2 brokers, and an Elasticsearch cluster that's accessible through a Route.
Keep in mind that this script doesn't create the Elasticsearch operator which Elasticsearch resource that is created in this script needs.
So first you will need to install the operator for Elasticsearch before running the helper script.
NOTE
If you are using Kubernetes you can create an Ingress and expose the Elasticsearch instance.
Exposing the Elasticsearch instance is not mandatory; you can access the Elasticsearch instance cluster internally.
Lastly create an empty repository in any image registry of your choice.
For this example we are going to use Quay.io as our repository will be quay.io/systemcraftsman/demo-connect-cluster.
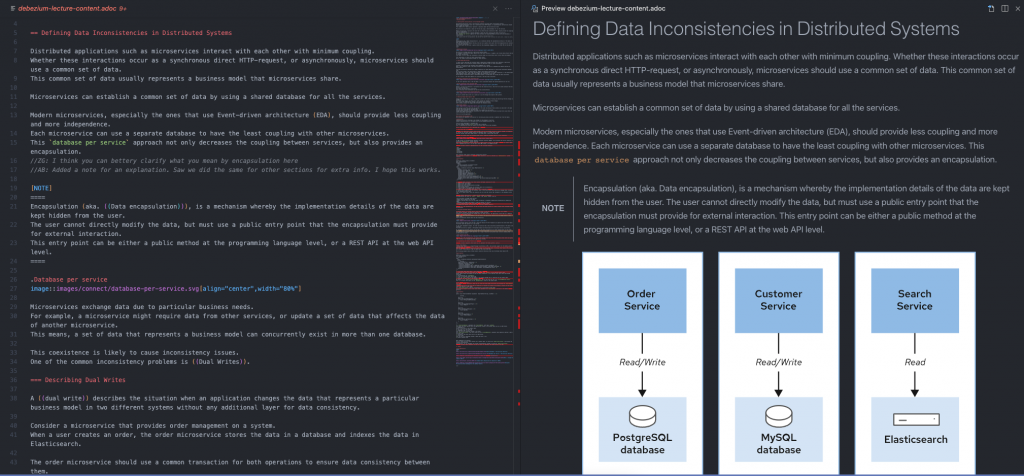
Creating a Kafka Connect Cluster with a Twitter Source Connector
For this example, to show how it is easy to create a Kafka Connect cluster with a traditional properties file, we will use an example of a well-known Kafka instructor, Stephane Maarek, who demonstrates a very basic Twitter Source Connector in one of his courses.
So let's clone the repository https://github.com/simplesteph/kafka-beginners-course.git and change directory into the kafka-connect folder in the repository.
In the repository we have this twitter.properties file which has the following config in it:
name=TwitterSourceDemo
tasks.max=1
connector.class=com.github.jcustenborder.kafka.connect.twitter.TwitterSourceConnector
# Set these required values
process.deletes=false
filter.keywords=bitcoin
kafka.status.topic=twitter_status_connect
kafka.delete.topic=twitter_deletes_connect
# put your own credentials here - don't share with anyone
twitter.oauth.consumerKey=
twitter.oauth.consumerSecret=
twitter.oauth.accessToken=
twitter.oauth.accessTokenSecret=
This connector get the tweets statuses or deletions and saves them into the twitter_status_connect or twitter_deletes_connect depending on the action.
The filter.keywords defines the keywords to be filtered for the returned tweets.
In this case it is set as bitcoin, so this will consume every tweet that has bitcoin and put it in the relevant topics.
Now let's make a few changes on this file regarding the content and restrictions that Strimzi has for topic names.
Copy the twitter.properties file and save it as twitter_connector.properties which you will be editing.
In the new file change the twitter_status_connect to twitter-status-connect which Strimzi will complain about since it is not a good name for a topic.
Normally Apache Kafka returns a warning about this but allows this underscore(_) convention.
Since Strimzi uses custom resources for managing Kafka resources, it is not a good practice to use underscores in the topic names, or in any other custom resource of Strimzi.
Also change the twitter_deletes_connect to twitter-deletes-connect and the connector name to twitter-source-demo for a common convention.
Enter your Twitter OAuth keys which you can get from your Twitter Developer Account.
For the creation of a Twitter Developer Account, Stephane explains this perfectly in his Kafka For Beginners course on Udemy.
So I recommend you to take a look at both the course and the twitter setup that is explained.
Finally, change the bitcoin filter to kafka for our demo (Or you can change it to anything that you want to see the tweets of).
The final connector configuration file should look like this:
name=twitter-source-demo
tasks.max=1
connector.class=com.github.jcustenborder.kafka.connect.twitter.TwitterSourceConnector
# Set these required values
process.deletes=false
filter.keywords=kafka
kafka.status.topic=twitter-status-connect
kafka.delete.topic=twitter-deletes-connect
# put your own credentials here - don't share with anyone
twitter.oauth.consumerKey=_YOUR_CONSUMER_KEY_
twitter.oauth.consumerSecret=_YOUR_CONSUMER_SECRET_
twitter.oauth.accessToken=_YOUR_ACCESS_TOKEN_
twitter.oauth.accessTokenSecret=_YOUR_ACCESS_TOKEN_SECRET_
Notice how little we changed (actually just the names) in order to use it in the Strimzi Kafka Connect cluster.
Because we are going to need the twitter-status-connect and twitter-deletes-connect topics, let's create them upfront and continue our configuration.
You must have remembered our kfk topics --create commands topics creation with Strimzi Kafka CLI:
$ kfk topics --create --topic twitter-status-connect --partitions 3 --replication-factor 1 -c my-cluster -n kafka
$ kfk topics --create --topic twitter-deletes-connect --partitions 3 --replication-factor 1 -c my-cluster -n kafka
Now let's continue with our Connect cluster's creation.
In the same repository we have this connect-standalone.properties file which has the following config in it:
...output omitted...
bootstrap.servers=localhost:9092
...output omitted...
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
...output omitted...
key.converter.schemas.enable=true
value.converter.schemas.enable=true
offset.storage.file.filename=/tmp/connect.offsets
# Flush much faster than normal, which is useful for testing/debugging
offset.flush.interval.ms=10000
...output omitted...
plugin.path=connectors
Kafka Connect normally has this plugin.path key which has the all connector binaries to be used for any connector created for that Connect cluster.
In our case, for Strimzi, it will be a bit different because we are going to create our connect cluster in a Kubernetes/OpenShift environment, so we should either create an image locally, or make Strimzi create the connect image for us.
We will use the second option, which is fairly a new feature of Strimzi.
Only thing we have to do, instead of defining a path, we will define a set of url that has the different connector resources.
So let's copy the file that Stephane created for us and save it as connect.properties since Kafka Connect works in the distributed mode in Strimzi (there is no standalone mode in short).
In the connect.properties file change the plugin.path with plugin.url and set the following source url to it:
plugin.url=https://github.com/jcustenborder/kafka-connect-twitter/releases/download/0.2.26/kafka-connect-twitter-0.2.26.tar.gz
By comparing to the original repository, you can see in the connectors folder there are a bunch of jar files that Twitter Source Connector uses.
The url that you set above has the same resources archived.
Strimzi extracts them while building the Connect image in the Kubernetes/OpenShift cluster.
Speaking of the image, we have to set an image, actually an image repository path, that Strimzi can push the built image into.
This can be either an internal registry of yours, or a public one like Docker Hub or Quay.
In this example we will use Quay and we should set the image URL like the following:
image=quay.io/systemcraftsman/demo-connect-cluster:latest
Here you can set the repository URL of your choice instead of quay.io/systemcraftsman/demo-connect-cluster:latest.
As a prerequisite, you have to create this repository and make the credentials ready for the image push for Strimzi.
Apart from the plugin.path, we can do a few changes like changing the offset storage to a topic instead of a file and disabling the key/value converter schemas because we will just barely need to see the data itself; we don't need the JSON schemas.
Lastly change the bootstrap.servers value to my-cluster-kafka-bootstrap:9092, as my-cluster-kafka-bootstrap is the my-cluster Kafka cluster's Kubernetes internal host name that is provided by a Kubernetes Service.
So the final connect.properties file should look like this:
...output omitted...
bootstrap.servers=my-cluster-kafka-bootstrap:9092
# The converters specify the format of data in Kafka and how to translate it into Connect data. Every Connect user will
# need to configure these based on the format they want their data in when loaded from or stored into Kafka
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
# Converter-specific settings can be passed in by prefixing the Converter's setting with the converter we want to apply
# it to
key.converter.schemas.enable=false
value.converter.schemas.enable=false
offset.storage.topic=connect-cluster-offsets
config.storage.topic=connect-cluster-configs
status.storage.topic=connect-cluster-status
config.storage.replication.factor=1
offset.storage.replication.factor=1
status.storage.replication.factor=1
...output omitted...
image=quay.io/systemcraftsman/demo-connect-cluster:latest
plugin.url=https://github.com/jcustenborder/kafka-connect-twitter/releases/download/0.2.26/kafka-connect-twitter-0.2.26.tar.gz
Again notice how the changes are small to make it compatible for a Strimzi Kafka Connect cluster.
Now lets run the Kafka Connect cluster in a way that we used to do with the traditional CLI of Kafka.
In order to start a standalone Kafka Connect cluster traditionally some must be familiar with a command like the following:
$ ./bin/connect-standalone.sh connect.properties connector.properties
The command syntax for Strimzi Kafka CLI is the same.
This means you can create a Connect cluster along with one or more connectors by providing their config properties.
The only difference is, Strimzi runs the Connect cluster in the distributed mode.
Run the following command to create to create a connect cluster called my-connect-cluster and a connector called twitter-source-demo.
Don't forget to replace your image registry user with _YOUR_IMAGE_REGISTRY_USER_.
$ kfk connect clusters --create --cluster my-connect-cluster --replicas 1 -n kafka connect.properties twitter_connector.properties -u _YOUR_IMAGE_REGISTRY_USER_ -y
IMPORTANT
You can also create the cluster with a more controlled way; by not passing the -y flag.
Without the -y flag, Strimzi Kafka CLI shows you the resource YAML of the Kafka Connect cluster in an editor, and you can modify or just save the resource before the creation.
In this example we skip this part with -y flag.
You should be prompted for the registry password.
Enter the password and observe the CLI response as follows:
secret/my-connect-cluster-push-secret created
kafkaconnect.kafka.strimzi.io/my-connect-cluster created
kafkaconnector.kafka.strimzi.io/twitter-source-demo created
IMPORTANT
Be careful while entering that because there is no mechanism that checks this password in Strimzi Kafka CLI, so if the password is wrong, simply the Connect image will be built sucessfully, but Strimzi won't be able to push it to the registry you specified before.
In case of any problem just delete the Connect cluster with the following command and create it again:
$ kfk connect clusters --delete --cluster my-connect-cluster -n kafka -y
Or you can delete/create the push secret that is created if you are experienced enough.
Now you can check the pods and wait till the Connect cluster pod runs without a problem.
$ watch kubectl get pods -n kafka
...output omitted...
my-connect-cluster-connect-8444df69c9-x7xf6 1/1 Running 0 3m43s
my-connect-cluster-connect-build-1-build 0/1 Completed 0 6m47s
...output omitted...
If everything is ok with the connect cluster, now you should see some messages in one of the topics we created before running the Connect cluster.
Let's consume messages from twitter-status-connect topic to see if our Twitter Source Connector works.
$ kfk console-consumer --topic twitter-status-connect -c my-cluster -n kafka
...output omitted...
{"CreatedAt":1624542267000,"Id":1408058441428439047,"Text":"@Ch1pmaster @KAFKA_Dev Of het is gewoon het zoveelste boelsjit verhaal van Bauke...
...output omitted...
Observe that in the console tweets appear one by one while they are created in the twitter-status-connect topic and consumed by the consumer.
As you can see we took a couple of traditional config files from one of the most loved Kafka instructor's samples and with just a few changes on the configuration, we could create our Kafka Connect cluster along with a Twitter Source connector easily.
Now let's take a step forward and try another thing.
What about putting these tweets in an elasticsearch index and make them searchable?
Altering the Kafka Connect Cluster
In order to get the tweets from the twitter-status-connect topic and index them in Elasticsearch we need to use a connector that does this for us.
Camel Elasticsearch REST Kafka Sink Connector is the connector that will do the magic for us.
First we need to add the relevant plugin resources of Camel Elasticsearch REST Sink Connector in our current connect.properties file that configures our Kafka Connect cluster.
Add the URL of the connector like the following in the connect.properties file:
...output omitted...
plugin.url=https://github.com/jcustenborder/kafka-connect-twitter/releases/download/0.2.26/kafka-connect-twitter-0.2.26.tar.gz,https://repo.maven.apache.org/maven2/org/apache/camel/kafkaconnector/camel-elasticsearch-rest-kafka-connector/0.10.0/camel-elasticsearch-rest-kafka-connector-0.10.0-package.tar.gz
...output omitted...
Now run the kfk connect clusters command this time with --alter flag.
$ kfk connect clusters --alter --cluster my-connect-cluster -n kafka connect.properties
kafkaconnect.kafka.strimzi.io/my-connect-cluster replaced
Observe the connector is being build again by watching the pods.
$ watch kubectl get pods -n kafka
Wait until the build finishes, and the connector pod is up and running again.
...output omitted...
my-connect-cluster-connect-7b575b6cf9-rdmbt 1/1 Running 0 111s
...output omitted...
my-connect-cluster-connect-build-2-build 0/1 Completed 0 2m37s
Because we have a running Connect cluster ready for a Camel Elasticsearch REST Sink Connector, we can create our connector now, this time using the kfk connect connectors command.
Creating a Camel Elasticsearch REST Sink Connector
Create a file called camel_es_connector.properties and paste the following in it.
name=camel-elasticsearch-sink-demo
tasks.max=1
connector.class=org.apache.camel.kafkaconnector.elasticsearchrest.CamelElasticsearchrestSinkConnector
value.converter=org.apache.kafka.connect.storage.StringConverter
topics=twitter-status-connect
camel.sink.endpoint.hostAddresses=elasticsearch-es-http:9200
camel.sink.endpoint.indexName=tweets
camel.sink.endpoint.operation=Index
camel.sink.path.clusterName=elasticsearch
errors.tolerance=all
errors.log.enable=true
errors.log.include.messages=true
Observe that our connector's name is camel-elasticsearch-sink-demo and we use the CamelElasticsearchrestSinkConnector class to read the tweets from twitter-status-connect topic.
Properties starting with camel.sink. defines the connector specific properties.
With these properties the connector will create an index called tweets in the Elasticsearch cluster which is accesible from elasticsearch-es-http:9200 host and port.
For more details for this connector, please visit the connector's configuration page link that we provided above.
Creating a connector is very simple.
If you defined a topic or another object of Strimzi via Strimzi Kafka CLI before, you will notice the syntax is pretty much the same.
Run the following command to create the connector for Camel Elasticsearch REST Sink:
$ kfk connect connectors --create -c my-connect-cluster -n kafka camel_es_connector.properties
kafkaconnector.kafka.strimzi.io/camel-elasticsearch-sink-demo created
You can list the created connectors so far:
$ kfk connect connectors --list -c my-connect-cluster -n kafka
NAME CLUSTER CONNECTOR CLASS MAX TASKS READY
twitter-source-demo my-connect-cluster com.github.jcustenborder.kafka.connect.twitter.TwitterSourceConnector 1 1
camel-elasticsearch-sink-demo my-connect-cluster org.apache.camel.kafkaconnector.elasticsearchrest.CamelElasticsearchrestSinkConnector 1 1
After the resource created run the following curl command in the watch mode to observe how the indexed values increases per tweet consumption.
Change the _ELASTIC_EXTERNAL_URL_ with your Route or Ingress URL of the Elasticsearch cluster you created as a prerequisite.
$ watch "curl -s http://_ELASTIC_EXTERNAL_URL_/tweets/_search | jq -r '.hits.total.value'"
In another terminal window you can run the console consumer again to see both the Twitter Source connector and the Camel Elasticsearch Sink connector in action:

In a browser or with curl, call the following URL for searching Apache word in the tweet texts.
$ curl -s http://_ELASTIC_EXTERNAL_URL_/tweets/_search?q=Text:Apache
{"took":3,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":3,"relation":"eq"},"max_score":5.769906,"hits":[{"_index":"tweets","_type":"_doc","_id":"bm6aPnoBRxta4q47oss0","_score":5.769906,"_source":{"CreatedAt":1624542084000,"Id":1408057673577345026,"Text":"RT @KCUserGroups: June 29: Kansas City Apache Kafka® Meetup by Confluent - Testing with AsyncAPI for Apache Kafka: Brokering the Complexity…","Source":"<a href=\"http://twitter.com/download/android\" rel=\"nofollow\">Twitter for Android</a>","Truncated":false,"InReplyToStatusId":-1,"InReplyToUserId":-1,"InReplyToScreenName":null,"GeoLocation":null,"Place":null,"Favorited":false,"Retweeted":false,"FavoriteCount":0,"User":{"Id":87489271,"Name":"Fran Méndez","ScreenName":"fmvilas","Location":"Badajoz, España","Description":"Founder of @AsyncAPISpec. Director of Engineering at @getpostman.\n\nAtheist, feminist, proud husband of @e_morcillo, and father of Ada & 2 cats \uD83D\uDC31\uD83D\uDC08 he/him","ContributorsEnabled":false,"ProfileImageURL":"http://pbs.twimg.com/profile_images/1373387614238179328/cB1gp6Lh_normal.jpg","BiggerProfileImageURL":"http://pbs.twimg.com/profile_images/1373387614238179328/cB1gp6Lh_bigger.jpg","MiniProfileImageURL":"http://pbs.twimg.com/profile_images/1373387614238179328/cB1gp6Lh_mini.jpg","OriginalProfileImageURL":"http://pbs.twimg.com/profile_images/1373387614238179328/cB1gp6Lh.jpg","ProfileImageURLHttps":"https://pbs.twimg.com/profile_images/1373387614238179328/cB1gp6Lh_normal.jpg","BiggerProfileImageURLHttps":"https://pbs.twimg.com/profile_images/1373387614238179328/cB1gp6Lh_bigger.jpg","MiniProfileImageURLHttps":"https://pbs.twimg.com/profile_images/1373387614238179328/cB1gp6Lh_mini.jpg","OriginalProfileImageURLHttps":"https://pbs.twimg.com/profile_images/1373387614238179328/cB1gp6Lh.jpg","DefaultProfileImage":false,"URL":"http://www.fmvilas.com","Protected":false,"FollowersCount":1983,"ProfileBackgroundColor":"000000","ProfileTextColor":"000000","ProfileLinkColor":"1B95E0","ProfileSidebarFillColor":"000000","ProfileSidebarBorderColor":"000000","ProfileUseBackgroundImage":false,"DefaultProfile":false,"ShowAllInlineMedia":false,"FriendsCount":3197,
...output omitted...
Cool!
We hit some Apache Kafka tweets with our Apache search in Twitter tweets related to kafka.
How about yours?
If you don't hit anything you can do the search with any word of your choice.
Since we are almost done with our example let's delete the resources one by one to observe how Strimzi Kafka CLI works with the deletion of the Kafka Connect resources.
Deleting Connectors and the Kafka Connect Cluster
First let's delete our connectors one by one:
$ kfk connect connectors --delete --connector twitter-source-demo -c my-connect-cluster -n kafka
kafkaconnector.kafka.strimzi.io "twitter-source-demo" deleted
$ kfk connect connectors --delete --connector camel-elasticsearch-sink-demo -c my-connect-cluster -n kafka
kafkaconnector.kafka.strimzi.io "camel-elasticsearch-sink-demo" deleted
Observe no more tweets are produced in the twitter-status-connect topic and no more data is indexed in Elasticsearch anymore.
Now we can also delete the my-connect-cluster Kafka Connect cluster.
Notice that it is pretty much the same with the Kafka cluster deletion syntax of Strimzi CLI.
$ kfk connect clusters --delete --cluster my-connect-cluster -n kafka -y
This command will both delete the KafkaConnect resource and the push secret that is created for the Connect image.
kafkaconnect.kafka.strimzi.io "my-connect-cluster" deleted
secret "my-connect-cluster-push-secret" deleted
Check the Connect cluster pod is terminated by the Strimzi operator:
$ kubectl get pods -n kafka
NAME READY STATUS RESTARTS AGE
elastic-operator-84774b4d49-v2lbr 1/1 Running 0 4h9m
elasticsearch-es-default-0 1/1 Running 0 4h8m
my-cluster-entity-operator-5c84b64ddf-22t9p 3/3 Running 0 4h8m
my-cluster-kafka-0 1/1 Running 0 4h8m
my-cluster-kafka-1 1/1 Running 0 4h8m
my-cluster-zookeeper-0 1/1 Running 0 4h8m
Congratulations!
In this example we are able to create a Kafka Connect cluster along with a Twitter Source connector with Strimzi Kafka CLI, to consume the tweets from Twitter and write them to one of our topics that we defined in the configuration.
We also altered the Kafka Connect Cluster and added new plugin resources for Camel Elasticsearch REST Sink connector, to write our tweets from the relevant topic to an Elasticsearch index with a single --alter command of Strimzi Kafka CLI.
This made our consumed tweets searchable, so that we could search for the word Apache in our tweets Elasticsearch index.
After finishing the example, we cleared up our resources by deleting them easily with the CLI.
If you are interested in more, check out the video that I create a Kafka Connect cluster and the relevant connectors in the article, using Strimzi Kafka CLI: