Messaging Architectures for Cloud-Native Applications

Table of Contents
Table of Contents
1. Traditional Applications and Monoliths
Do you remember the times we used to create applications by creating data models regarding the business domains and use those data models as the reflection of the relational database objects -mostly tables- in order to do CRUD actions?
Business requirements were pouring from the waterfall and making us so soaking wet that we could not easily respond to change: new business requirements, bug fixes, enhancements, etc.
When Agile methodologies came out, after some time, this made us more flexible and respond to change very quickly whereas there came out some ideas of SOA, service bus, distributed state management, etc. but business domains stayed kind of merged and monoliths survived.
Monolith applications -which is actually not an anti-pattern- ruled the world for a considerable number of years with different kinds of architectures that have their own benefits and drawbacks.
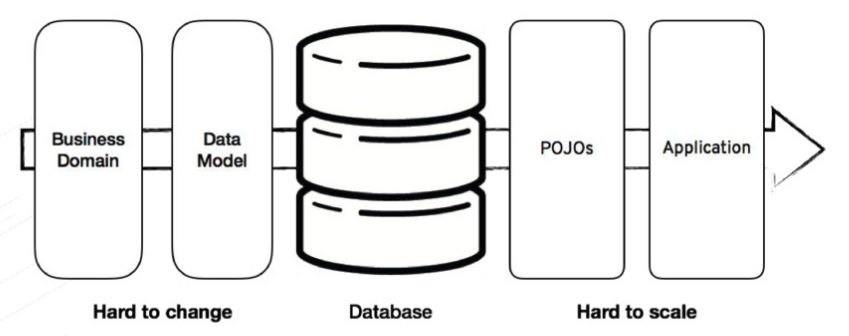
Figure 1. Traditional Application Design. https://speakerdeck.com/mbogoevici/data-strategies-for-microservice-architectures?slide=4
1.1. Benefits and Drawbacks
The Benefits:
- Easy to start with
- Easy transaction management
- Sync communication
- Can be powered-up with the modular architecture
The Drawbacks:
- Hard to change business domain and data model
- Hard to scale
- Tightly coupled components
2. Cloud-Native Applications and Microservices
One of the best motivations for approaches like Domain Driven Design is being monoliths’ tightly coupled between business domains and the need of separating those domains in order to loosen the coupling and provide single responsibility for each domain as bounded contexts.
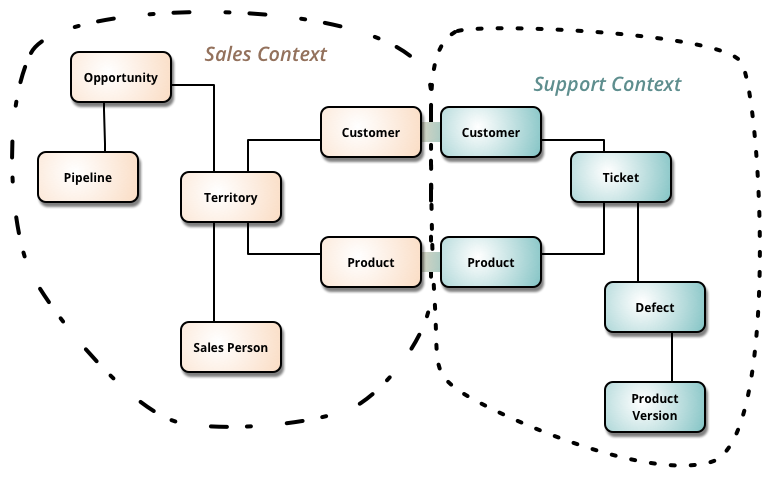
Figure 2. Bounded Contexts. https://martinfowler.com/bliki/BoundedContext.html
So these kinds of approaches led to microservices’ creation with the motivation of loosely coupling between bounded contexts, being polyglot, which means using best-fitting tools for the relevant service, easily being scalable horizontally, and most importantly with these benefits, being able to easily adapt into the could-native world.
Apart from creating a lot of benefits on the microservices side, microservices and the cloud-native application architecture has some challenges that may turn a developer’s life into a nightmare.
2.1. Challenges
Microservice architectures have many challenges like manageability of the services, traceability, monitoring, service discovery, distributed state and data management, and resilience which are handled automatically by cloud-native platforms like Kubernetes. For example service discovery is one of the requirements of an application that consists of microservices and Kubernetes provides this service discovery mechanism on its own side.
What cloud-native platforms can not provide and leave it to the guru developers is state management itself.
2.1.1. State
In order to keep the state in a distributed system and make it flew through the microservices has some challenges. Keeping the state in a distributed cache system like Infinispan and create a kind of single source of truth for the state is a common pattern but in the mesh of the service, it is tough to manage since there will be an Inception of caches.
Keeping the state distributed through services is even tougher.
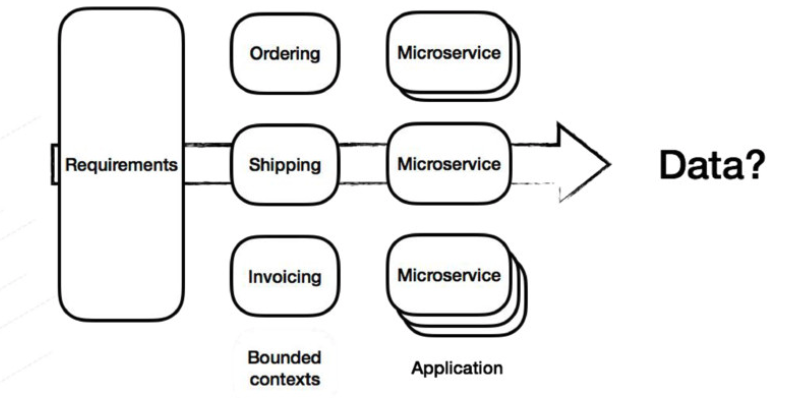
Figure 3. Microservices & Data. https://speakerdeck.com/mbogoevici/data-strategies-for-microservice-architectures?slide=5
As Database-per-microservice is a common pattern and as each bounded context should have and handle its own data, -with the need of sharing the state/data through services- this makes direct point-to-point communication between microservices more important.
2.1.2. Synchronous Communication
Synchronous data retrieval is a way to get the data that is needed from a microservice to another microservice. One can use comparingly new technologies like HTTP+REST, gRPC, or some old school technologies like RMI and IIOP, but all these synchronous point-to-point styles of data retrieval have some costs.
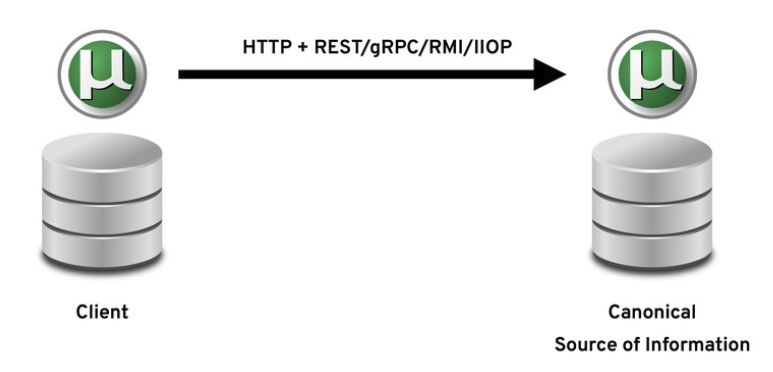
Figure 4. Synchronous Data Retrieval. https://speakerdeck.com/yanaga/distribute-your-microservices-data-with-events-cqrs-and-event-sourcing?slide=5
Latency is one of the key points of messaging between services and with synchronous communication if one of the services whose data will be retrieved has some performance problems in itself, it will be able to serve the data with a bit of latency that may cause data retrieval latency or timeout exceptions.
Or a service may have some failure inside and is not available that specific time period the sync data call won’t work.
Also, any performance issues on the network will directly either affect the latency or service availability. So it is up to the network’s being reliable.
We know that there are some patterns like distributed caching, bulkhead, and circuit breaker patterns for handling this kind of failure scenario by implementing fault tolerance strategies, but is it really the right way to do it?
2.2. Challenging the Challenges
So there are some solutions which some of them are invented years ago, but still rigid enough to be a ‘solution’ while others are brand-new architectures that will help us for challenging the challenges of cloud-native application messaging and communications.
Let’s start by taking a look at the common asynchronous messaging architectures before jumping into the solutions.
2.2.1. Asynchronous Messaging and Messaging Architectures
Like synchronous communication, asynchronous communication -or in other words messaging– has to be done over protocols. Two sides of the communication should agree on the protocol, so that message data that is either forecasted or consumed can be understood by the consumer.
While HTTP+REST protocol is the most used protocol for synchronous communication, there are several other protocols that asynchronous messaging systems widely use; like AMQP, STOMP, XMMP, MQTT, or Kafka protocols.
There are three main types of messaging models:
- Point-to-point
- Publish-subscribe (Pub-sub)
- Hybrid
Point-to-Point
Point-to-point messaging is like sending a parcel via mail post services. You go to a post office, write the address you want the parcel to be delivered to, and post the parcel knowing it will be delivered sometime later. The receiver does not have to be at home when the parcel is sent and at some point later the parcel will be received at the address.
Point-to-point messaging systems are mostly implemented as queues that use the first-in, first-out (FIFO) order. So this means that only one subscriber of a queue can receive a specific message.
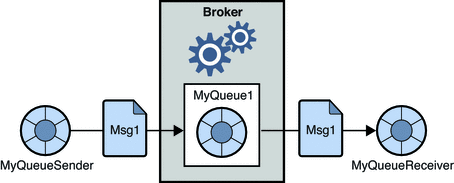
Figure 5. Point-to-Point Messaging. https://docs.oracle.com/cd/E19340-01/820-6424/aerbj/index.html
This opens the conversation of queues are being durable, which means if there are no active subscribers the messaging system will retain the messages until a subscriber comes and consumes them.
Point-to-point messaging is generally used for the use cases of calling for a message to be acted upon once only as queues can best provide an at-least-once delivery guarantee.
Publish-Subcribe
In order to understand how publish-subscribe (pub-sub) works think that you are an attendee on a webinar. When you are connected you can hear and watch what the speaker says, along with the other participants. When you disconnect you miss what the speaker says, but when you connect again you are able to hear what is being said.
So the webinar works like a pub-sub mechanism that while all the attendees are subscribers, the speaker is the broadcaster/publisher.
Pub-sub mechanisms are generally implemented through topics that act like the webinar broadcast to be subscribed. So when a message is produced on a topic, all the subscribers get it since the message is distributed along.
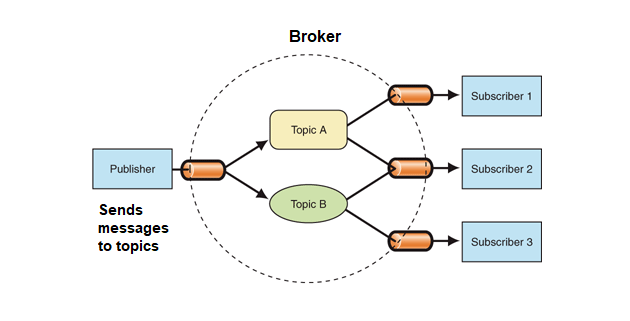
Figure 6. Publish-Subscribe Messaging. https://engineering.carsguide.com.au/laravel-pub-sub-messaging-with-apache-kafka-3b27ed1ee5e8
Topics are nondurable, unlike the queues. This means that a subscriber/consumer that is not consuming any messages -as it might be not running etc.-, misses the broadcasted messages in that period of being off. So this means that topics can provide a at-most-once delivery guarantee for each subscriber.
Hybrid model
Hybrid models of messaging systems both include the point-to-point and publish-subscribe as the use cases generally require a messaging system that has many consumers who want a copy of the message with full durability; in other words without message loss.
Technologies like ActiveMQ and Apache Kafka both implement this hybrid model with their own ways of persistence and distribution mechanisms.
Durability is a key factor especially on Cloud-Native distributed systems since the persistence of the state and being able to somehow replay it plays a key role in component communication. By adding it the capabilities of the publish-subscribe mechanism decrease the dependencies between components/services/microservices as it has the power of persisting and getting the message again either with the same subscriber or another one.
So the hybrid messaging systems are very vital when it comes to passing states as messages through Cloud-Native microservices as events since event-driven distributed architectures require these capabilities.
2.2.2. Events & Event Sourcing
As a process of developing microservice-based cloud-native architectures, approaches like Domain-Driven Design (DDD) makes it easy to divide the bounded contexts and see the sub-domains related to the parent domain.
One of the best techniques to separate and define the bounded contexts is the Event Storming technique, which takes the events as entry points and emerges everything including commands, data relationships, communication styles, and most importantly combobulators which are mostly mapped as bounded contexts.
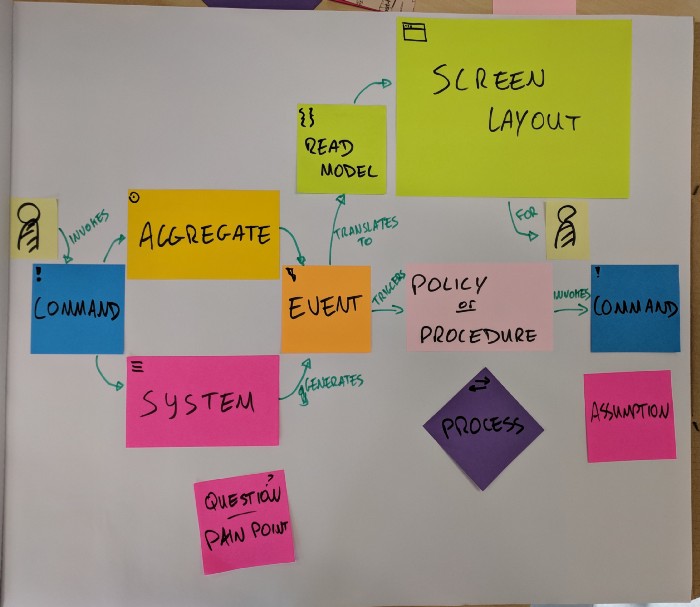
Figure 7. Events Storming Components. https://medium.com/@springdo/a-facilitators-recipe-for-event-storming-941dcb38db0d
After all when most of the event storming map emerges, one can see all communication points between bounded contexts which are mostly mapped as microservices or services in the system that has their own database and data structure.
Figure 8. A real-life Event Storming example;)
This structure, as it all consists of events, gives the main idea of using async communication via a publish-subscribe system that queues the events to be consumed, in other words, doing Event Sourcing.
Event Sourcing is a state-event-message pattern that captures all changes to an application state as a sequence of events that can be consumed by other applications -in this case, microservices.
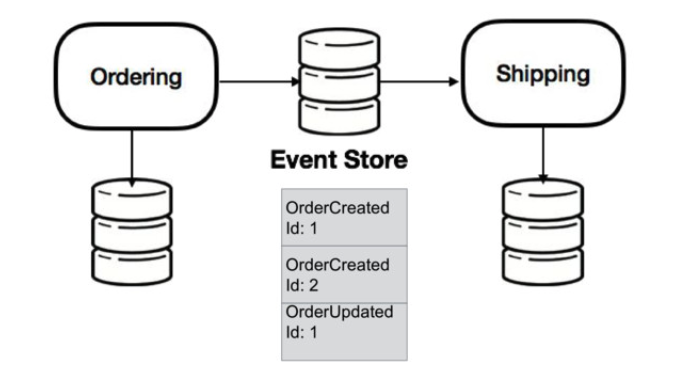
Figure 9. Event Sourcing. https://speakerdeck.com/mbogoevici/data-strategies-for-microservice-architectures?slide=14
Event Sourcing is very important in a distributed cloud-native environment because in the cloud-native world microservices can easily be scaled, new microservices can join or -from an application modernization perspective- microservices can be separated from their big monolith mother in order to make it live its own life.
So having the capability of an asynchronous publish-subscribe system that has the durability of data or ability to replay is very important. Additionally, queueing the events rather than the final data makes it flexible for other services which means implementing dependency inversion in an asynchronous environment with the capability of eventual consistency.
The question here is: How to create/trigger those events?
There are many programmatic ways rather than languages or framework libraries to create events and publish them. One can create database listeners or interceptors programmatically (like Hibernate Envers does) or can handle them in the DAO (Data Access Object) or service layer of the application. Even so, creating an Event Sourcing mechanism is not easy.
At this point, a relatively new pattern comes as a savior: Change Data Capture.
2.2.3. Change Data Capture
Change Data Capture (CDC) is a pattern that is used to track the data change -mostly in databases- in order to take any action on it.
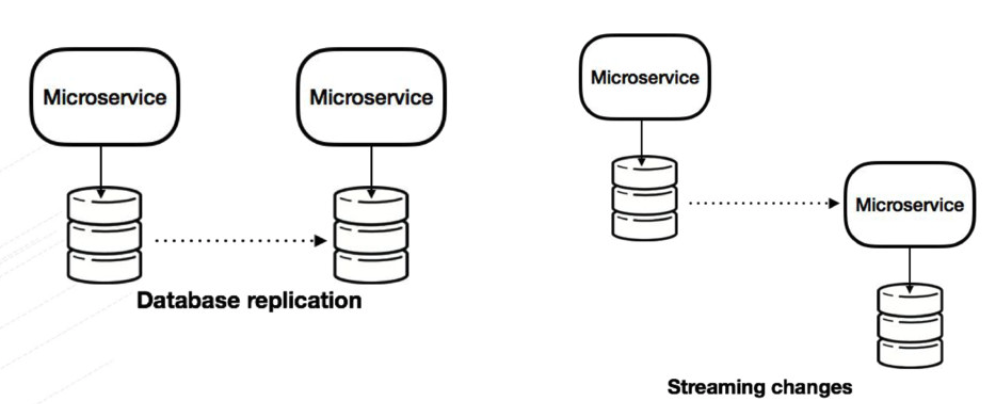
Figure 10. Change Data Capture. https://speakerdeck.com/mbogoevici/data-strategies-for-microservice-architectures?slide=15
A CDC mechanism should listen to the data change, and create the event that includes the change as Create, Insert, Update, Delete actions, and the data change itself. After creating the action it can be published to any durable pub-sub system in order to be consumed.
In order to decouple the database change event listening capability from the application code, it is one of the best patterns that is used for event-driven architectures of cloud-native applications.
Debezium is probably the most popular open-source implementation nowadays because of its easy integration with a popular set of databases and Apache Kafka, especially on platforms like Kubernetes/OpenShift.
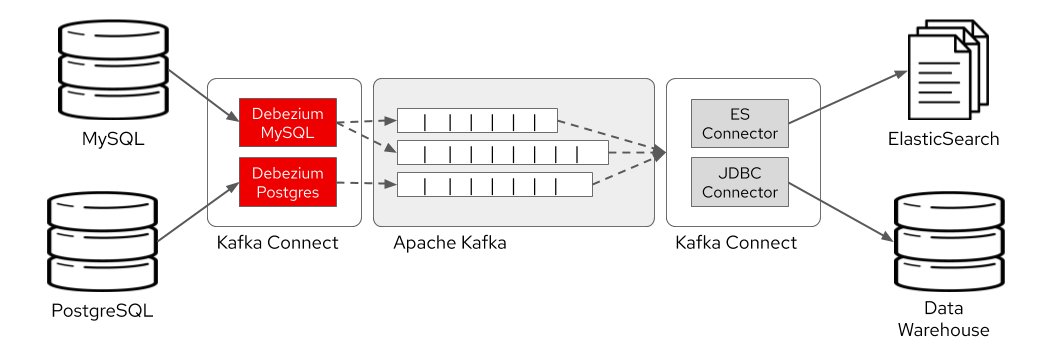
Figure 11. CDC with Debezium. https://developers.redhat.com/blog/2020/04/14/capture-database-changes-with-debezium-apache-kafka-connectors/
Now that, we have our event sourcing listener and creator as a CDC implementation like Debezium and let’s say we use Apache Kafka for event distribution between microservices.
Since the data we are creating is not the data itself but the change subscribed microservice should get the change and reflect it to its database. This change -when it comes again a microservice having a database of its own because it’s being a bounded context– is generally used for the read purpose rather than its being a write on the database because it is a reflection of the event that is just triggered by another write on another database.
So this makes us recall a pattern -that is already automatically implemented by design in the sample of ours- that’s been used for many years especially by enterprise-level relational databases: CQRS.
2.2.4. Command Query Responsibility Segregation (CQRS)
CQRS is a pattern that suggests one to separate the read model from the write model, mainly with the motivation of separation of concerns and performance.
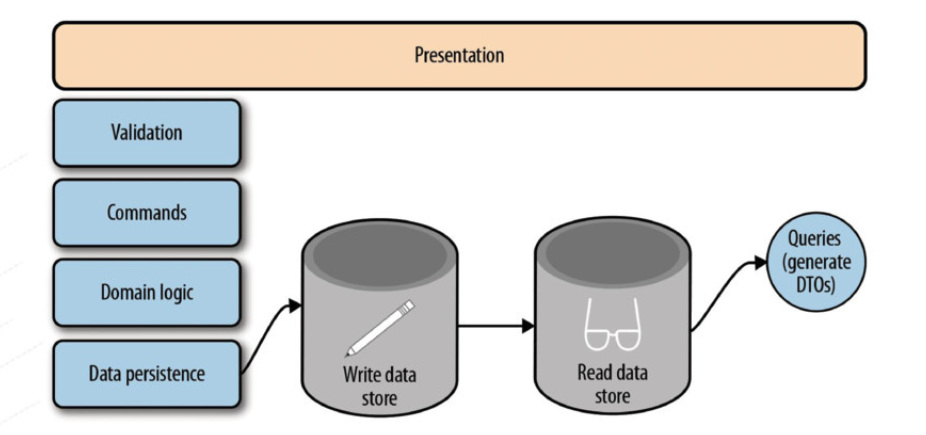
Figure 12. CQRS with Separate Datastores. https://speakerdeck.com/mbogoevici/data-strategies-for-microservice-architectures?slide=20
In a cloud-native system that has a set of polyglot microservices that has its own database -either as relational or NoSQL- the CQRS pattern fits well since each microservice has to have the data reflection of the dependent/dependee application.
2.3. Solutions Assemble: State Propagation
So in our imaginary, well-architected, distributed cloud-native system, in order to make our microservices communicate and transfer their state, we called the best of breed super-heroic patterns -some of which has great implementations.
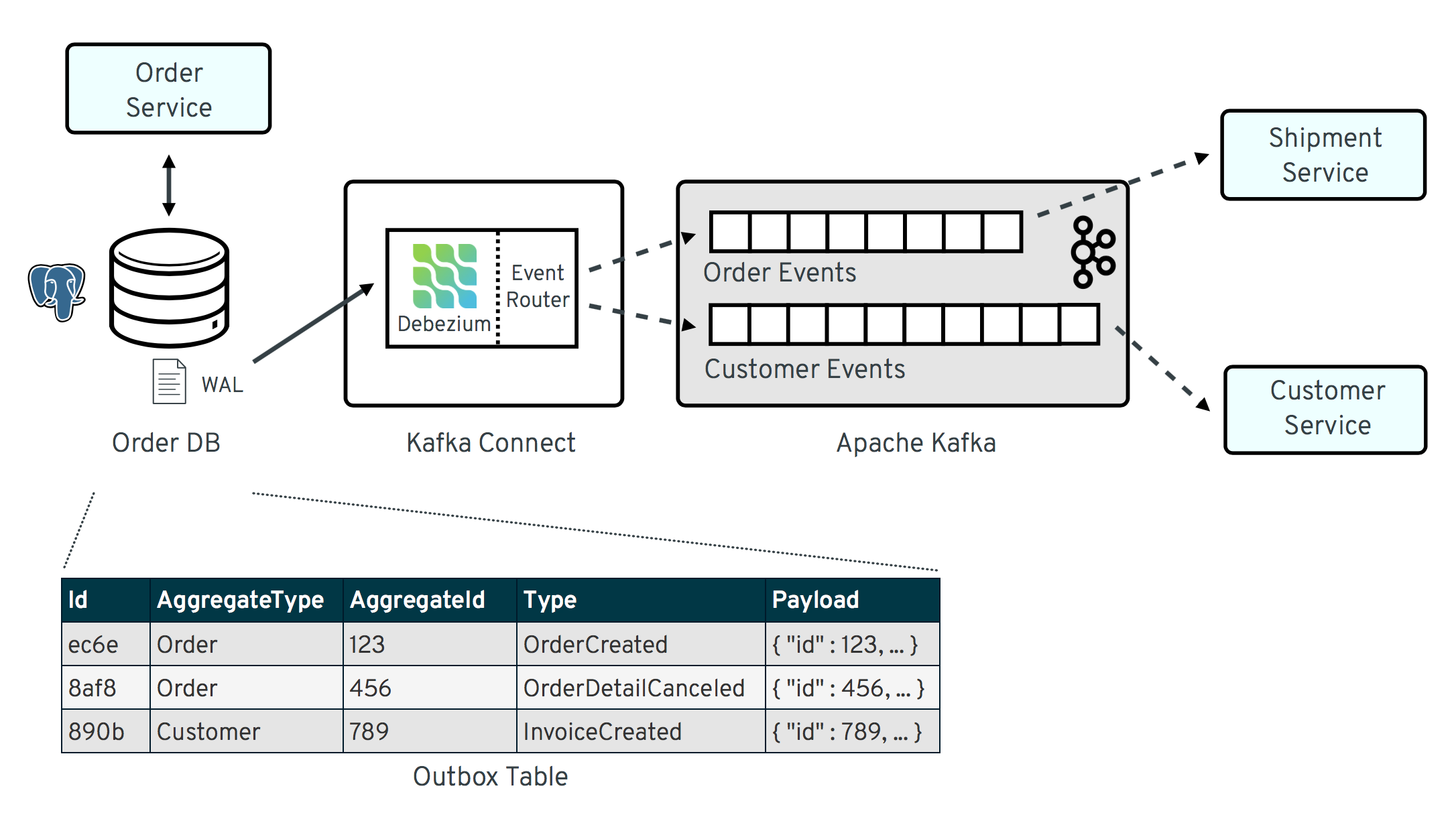
Figure 13. State Propagation & Outbox Pattern. https://debezium.io/blog/2019/02/19/reliable-microservices-data-exchange-with-the-outbox-pattern/
This state transfer through an asynchronous system that has the durability and pub-sub ability like Apache Kafka, triggered by a change data capture mechanism like Debezium, writing to a component which creates the event data to be read by another component is all called State Propagation which is backed by the Outbox pattern on the microservices side.
To sum up all, getting all the solutions altogether state propagation and creating event-driven mechanisms with CDC, Event Sourcing and CQRS help us in a very elegant way in order to solve the challenges of the cloud-native microservices era.
Resources
Books
- Jakub Korab. ‘Understanding Message Brokers’. O’Reilly Media, Inc. ISBN 9781491981535.
- Todd Palino, Gwen Shapira, Neha Narkhede. ‘Kafka: The Definitive Guide’. O’Reilly Media, Inc. ISBN 9781491936160.
Videos
- Gwen Saphira. ‘Cloud native data pipelines with Apache Kafka’. https://learning.oreilly.com/videos/cloud-native-data/0636920333746/0636920333746-video328373
- Edson Yanaga. ‘Distribute Your Microservices Data With Events, CQRS, and Event Sourcing’. https://www.youtube.com/watch?v=HdvWfr2KwA0
- Marius Bogoevici, Edson Yanaga. ‘Data Strategies for Microservice Architectures’. https://www.youtube.com/watch?v=n_V8hBRoshY
Presentations
- Edson Yanaga. ‘Distribute Your Microservices Data With Events, CQRS, and Event Sourcing’. https://speakerdeck.com/yanaga/distribute-your-microservices-data-with-events-cqrs-and-event-sourcing
- Marius Bogoevici. ‘Data Strategies for Microservice Architectures’. https://speakerdeck.com/mbogoevici/data-strategies-for-microservice-architectures
Website Articles
- Open Practice Library. ‘Event Storming’. https://openpracticelibrary.com/practice/event-storming/
- Donal Spring. ‘A facilitators recipe for Event Storming’. https://medium.com/@springdo/a-facilitators-recipe-for-event-storming-941dcb38db0d
- Martin Fowler. ‘Bounded Context’. https://martinfowler.com/bliki/BoundedContext.html
- Martin Fowler. ‘CQRS’. https://martinfowler.com/bliki/CQRS.html
- Martin Fowler. ‘Event Sourcing’. https://martinfowler.com/eaaDev/EventSourcing.html